contents: 0-1. CA Intro
Because the longest delay determines clock period, a single-cycle implementation is not used today
It violates "make the common case fast"
Pipelining overview
With the pipelined approach, the speed up can be equal to the number of stages in an ideal case
-
A single task is divided into N stages
-
Each stage takes teh same amount of time T
-
There are M tasks, where M is large enough
To complete all the tasks
-
In non-pipelined approach, we need times
-
In pipelined approach, we need time
Stage in pipeline
For different stages, different resources are used.
-
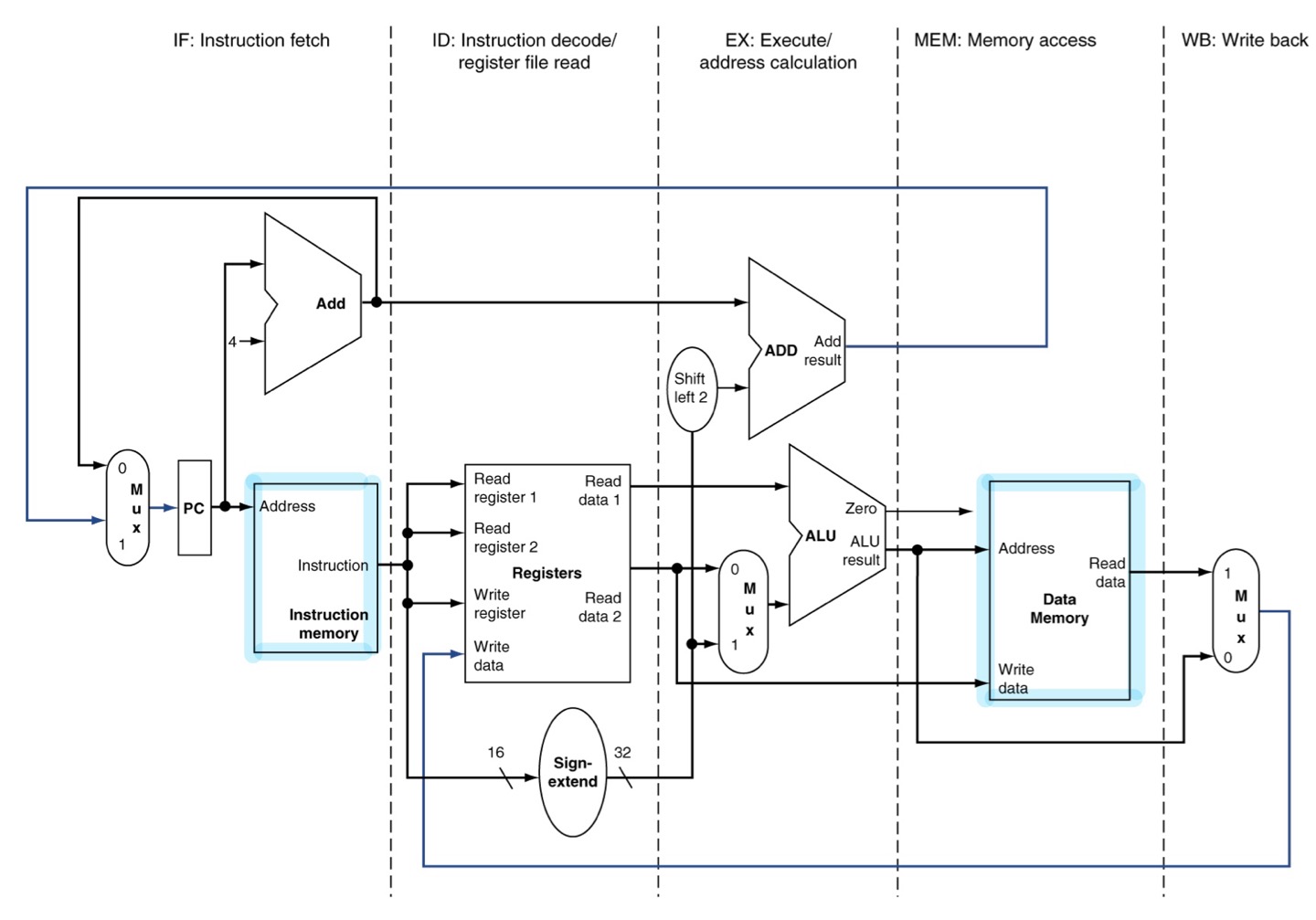
Stage 1: IF (Fetching an instruction from memory)
-
Stage 2: ID (Decoding the instruction and read registers)
-
Stage 3: EX (Executing operation or calculating address)
-
Stage 4: MEM (Accessing data in data memory)
-
Stage 5: wB (Writing the result back into a register)
Compared to the single-cycle processor
Compared to the single cycle processor, clock period in pipelined processor is determined by the longest stage time.
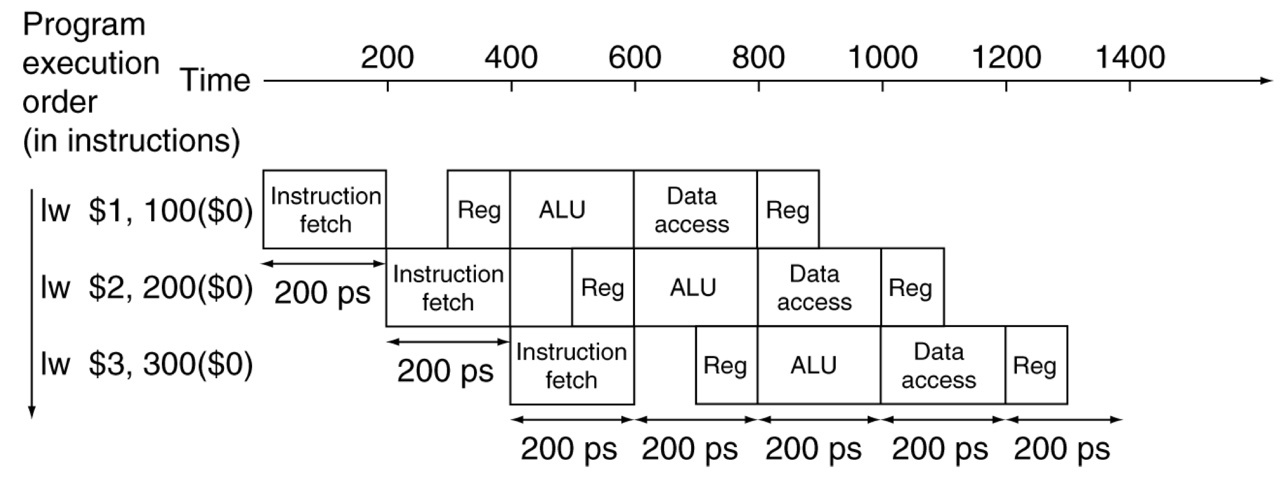
If there are a lot of instructions to be executed,
Hazards in Pipelining
- Structural hazards
- When a required resources is busy
- Data hazards
- When we need to wait for previous instruction to complete its data read/write operation
- Control hazards
- When we need to make a control decision differently depending on the previous instruction
Structural hazards
When a required resource is already used for executing an other instruction
-
IF and MEM stages can request to use the same resource at the same time
-
it is required to separate instruction / data memories
- IF and MEM stages use different part of memory (instruction memory, data memory)
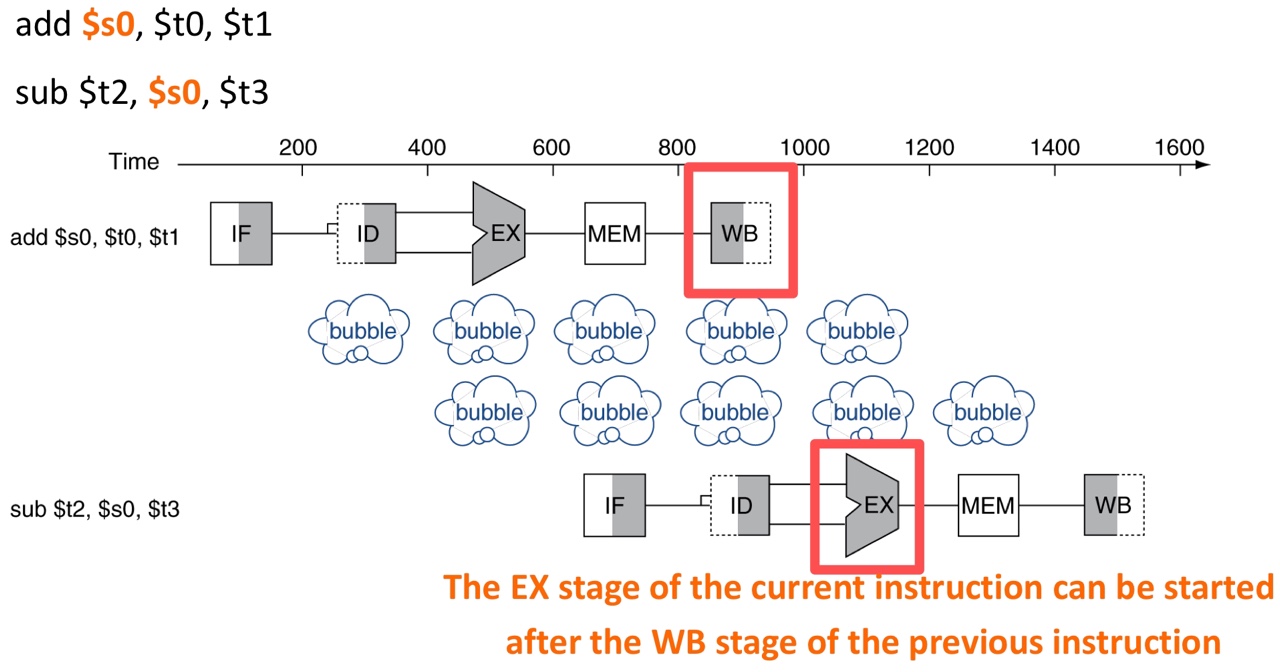
Data hazards
When an instruction depends on the completion of data access by a previous instruction
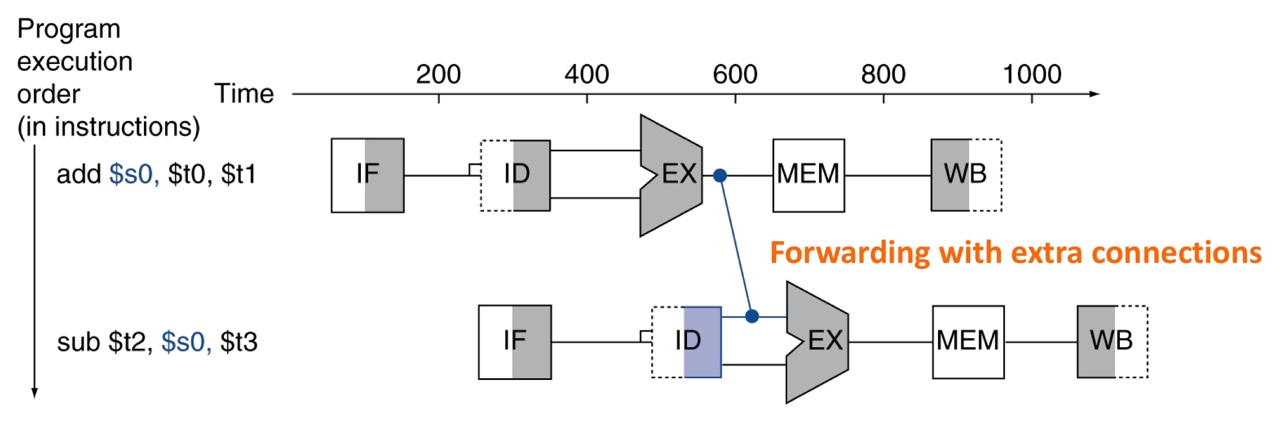
Solution: Forwarding
Instead of waiting for the target date to be stored in a register,
forward the data as soon as possible with extra connections
Load-use data hazards
But, sometimes, we cannot avoid stalls by forwarding
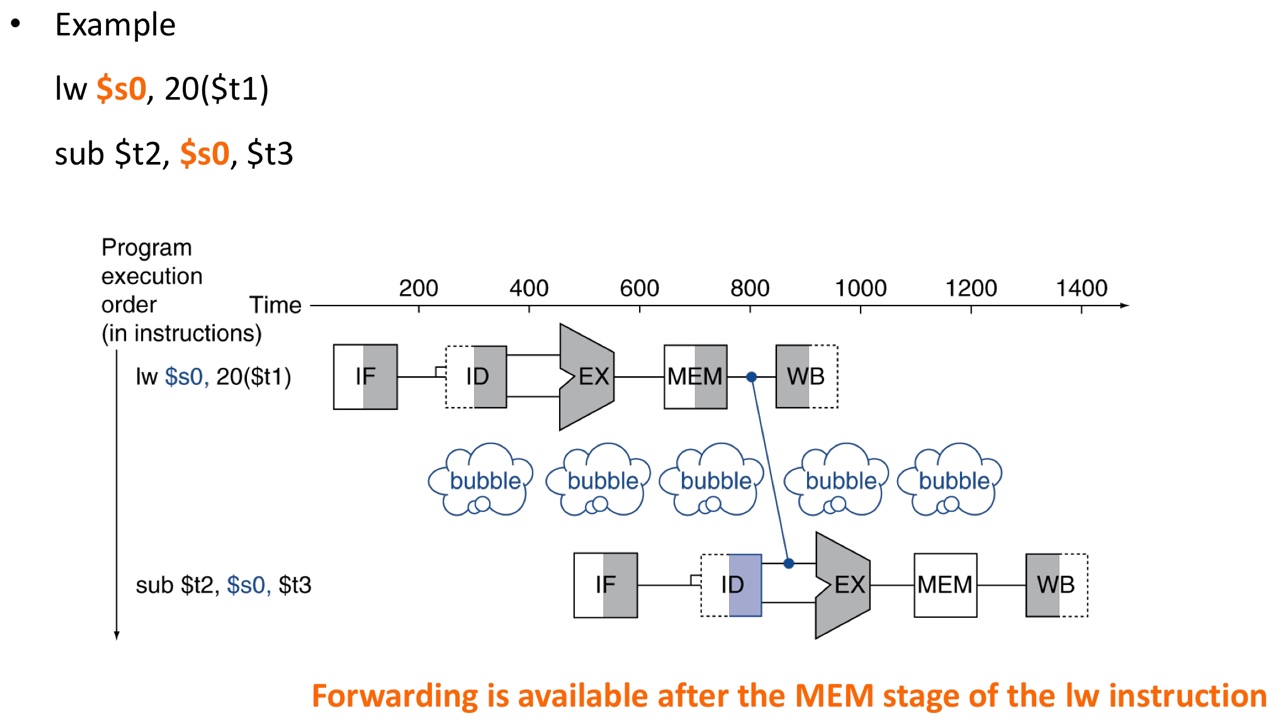
Solution: code scheduling
Reorder code to avoid the load-use data hazards (done by compiler)
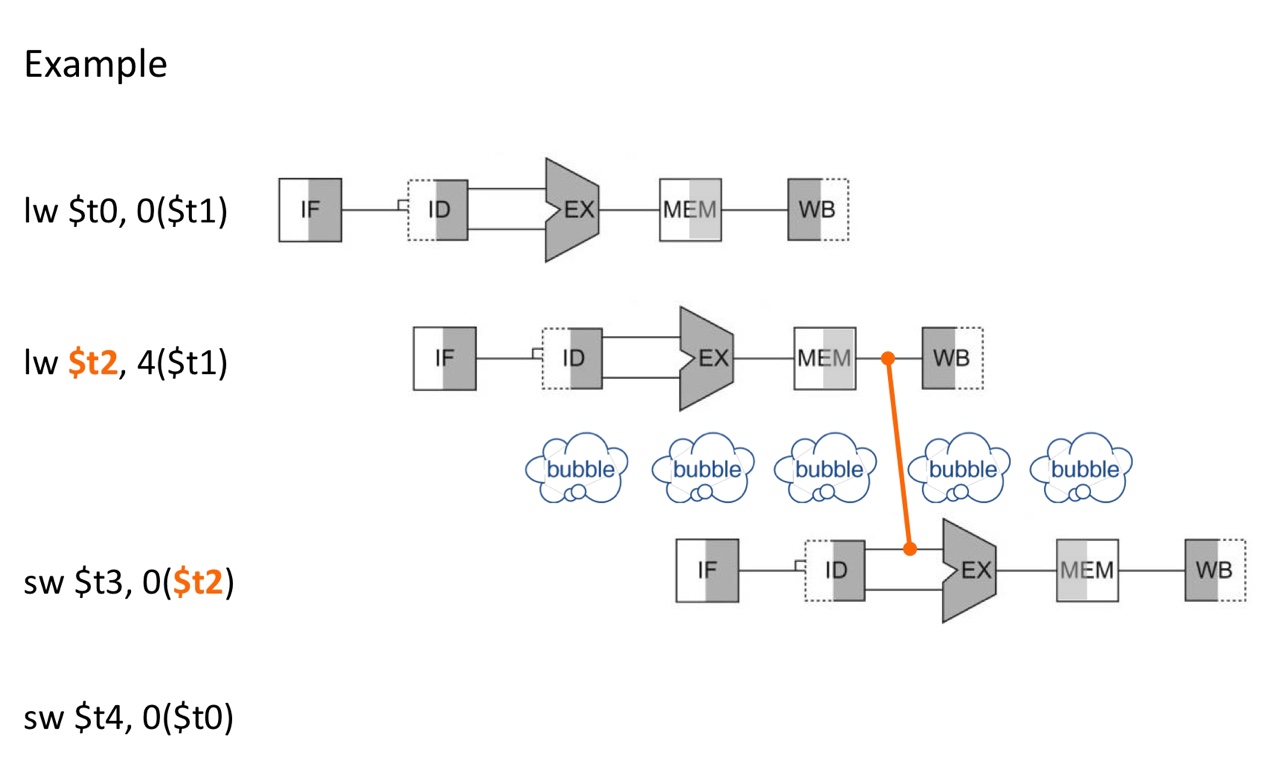 before
before
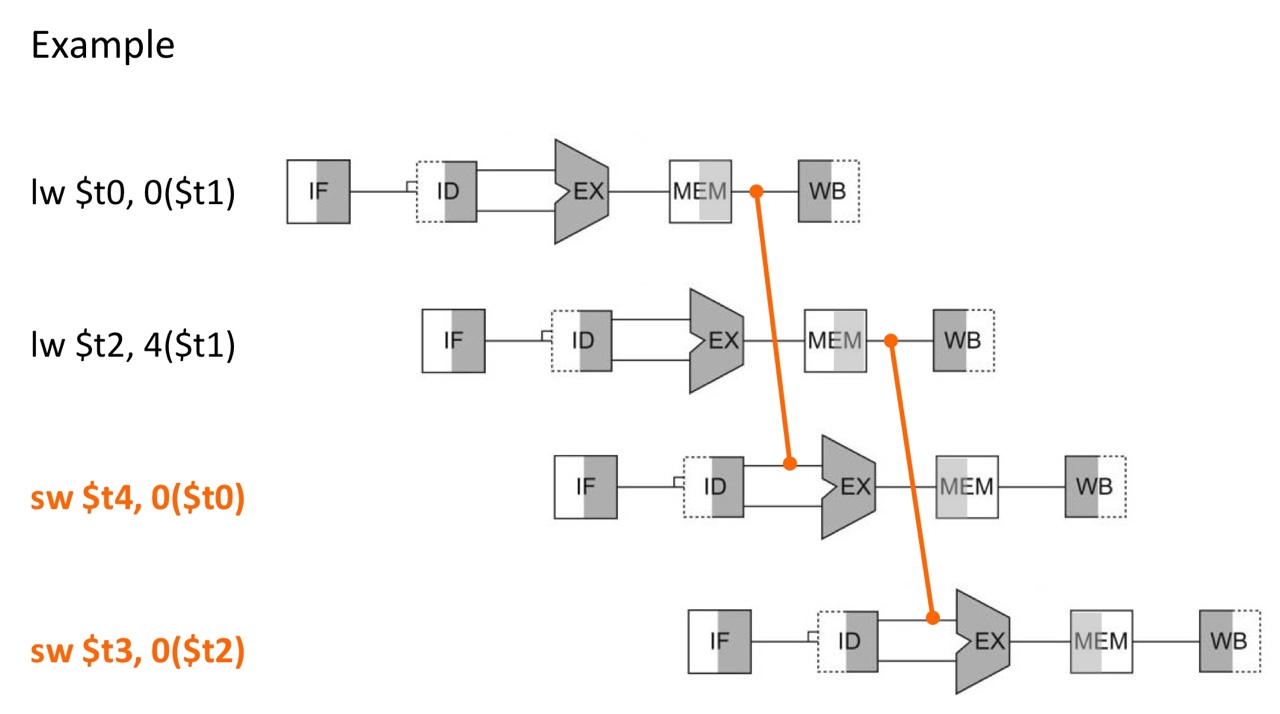 after
after
Control hazards
Hazards with branch instructions
We should wait until branch outcome is determined before fetching the next instruction
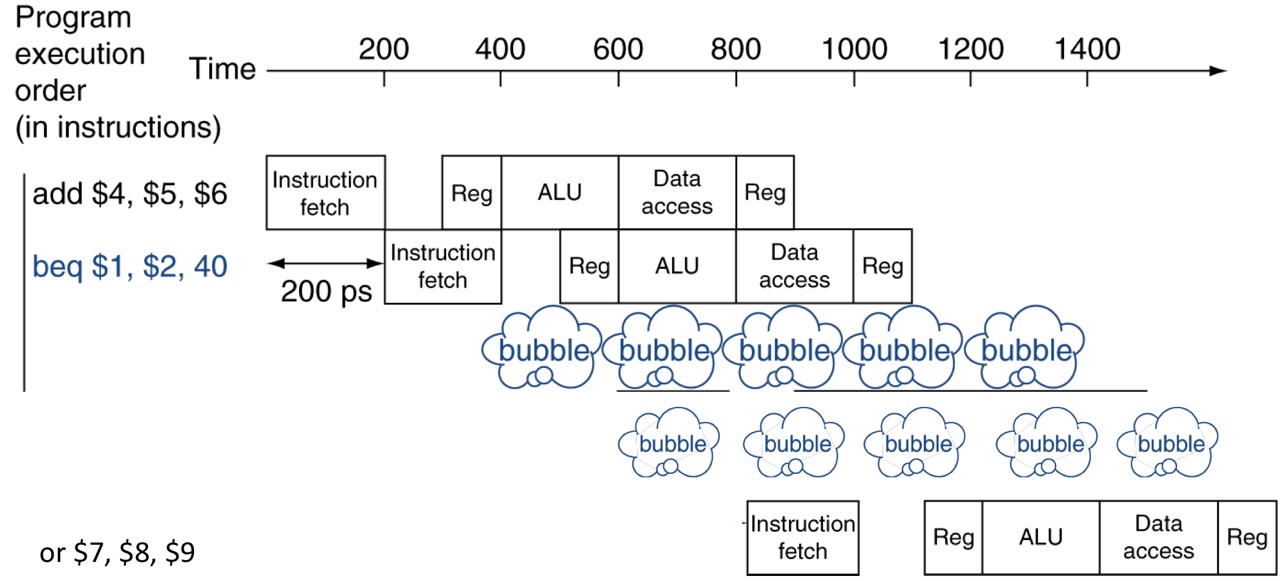
Solution: Compare registers and compute target early in the pipeline
-
Especially, by adding hardware to do it in ID stage
-
But, still there is one pipeline bubble
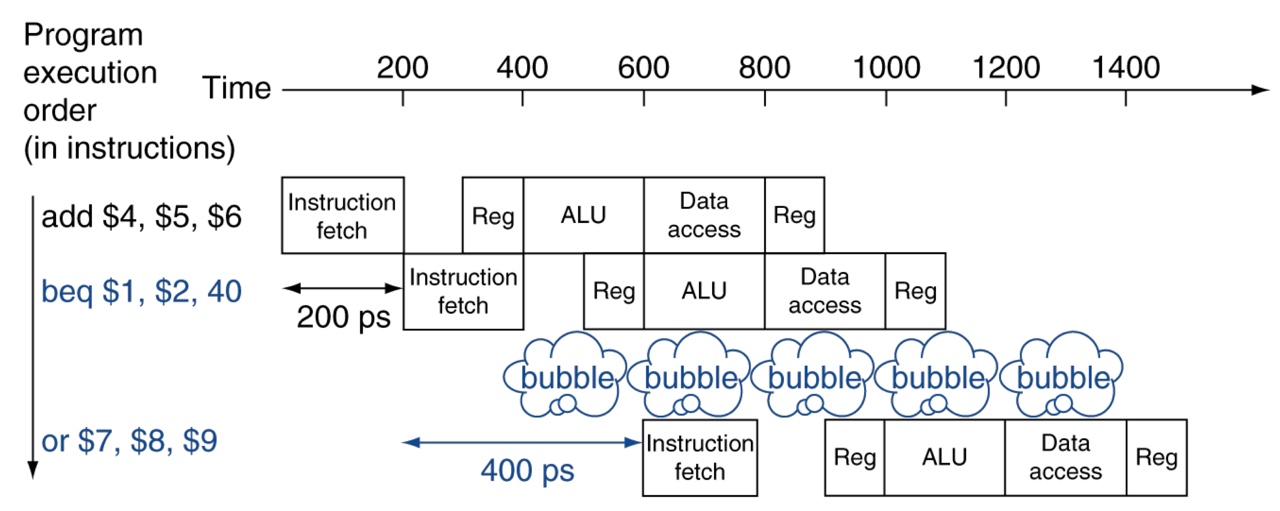
Solution: branch prediction
With additional HW for early comparison and computation in ID stage
- just fetch instruction with no bubble
- if prediction correct: keep going
- if prediction incorrect: cancel the process & add bubble
Summary
Pipelining improves performance by increasing instruction throughput
-
Executes multiple instructions in parallel
-
The execution time of each instruction is not affected
Pipeline hazards
- Structural hazards
- Solution: separate data / instruction memories
- (Load-use) Data hazards
- Solution: forwarding + code scheduling
- Control hazards
- Solution: early comparison & computation + branch prediction